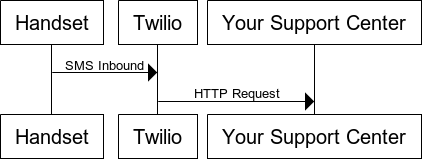
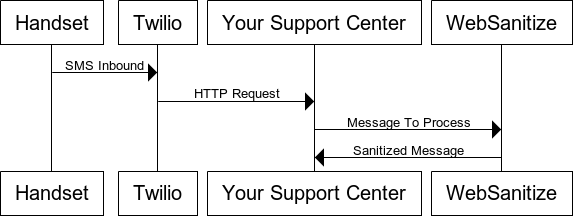
Recently Twilio released a new product called Studio, which is a graphical drag and drop editor you can use to build workflows, IVR’s and bots – both via voice and SMS channels. Over the last little while, I’ve been using Studio to build some awesome bots.
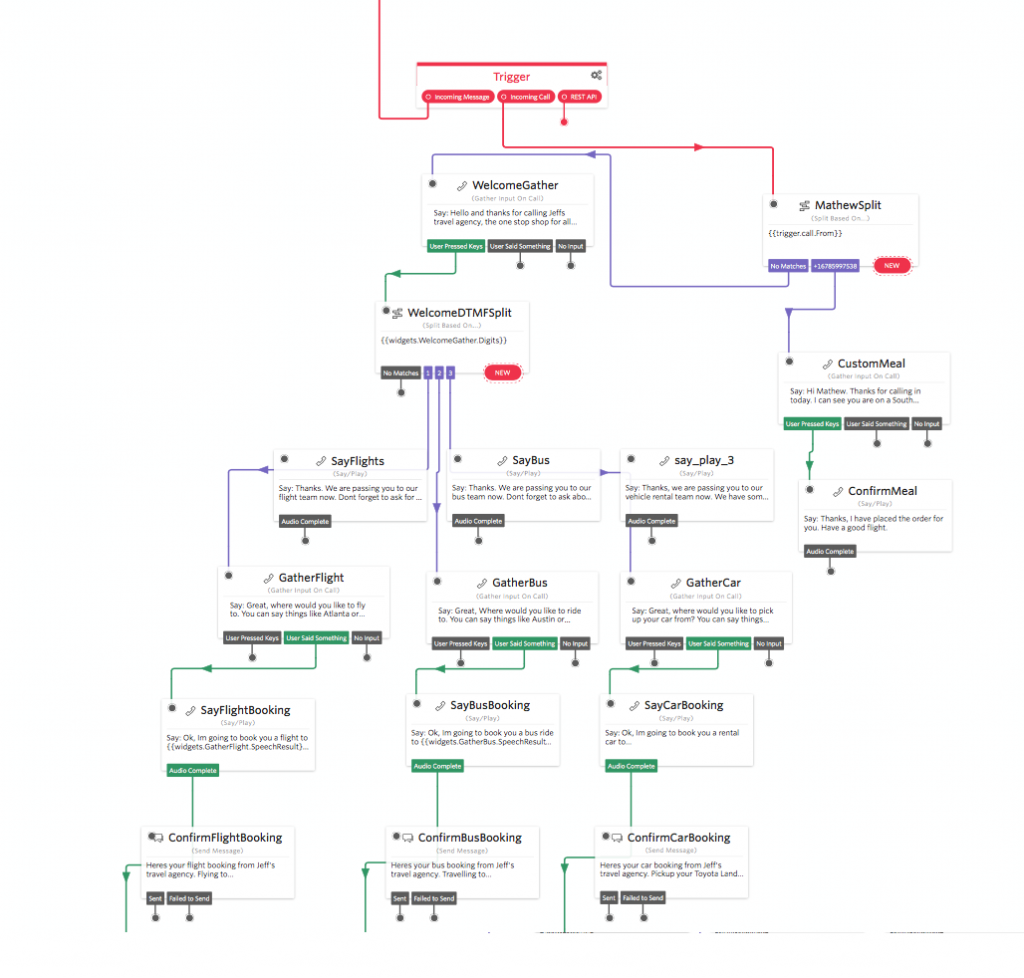
One of the bots that I have built is a blacklisting tool that prevents my apps from spamming and messaging unwanted users, this tool uses another product of Twilio called ‘functions’ which is essentially AWS Lambda but executed within the Twilio ecosystem.
To do this project I found a great service called BanishBot, which dub’s itself as ‘An API designed to help you manage opt-in/out communications and access lists.’ In short, its an API you can use in distributed systems to manage your opt-in and out lists.
In this post, I’m going to use Studio, Functions, and BanishBot to create an auto-updating opt-in/out application. At the end of the build, I’ll have a system where customers/people can automatically opt-in or out of my messages. I’ll then be able to use BanishBot in my application development as the last mile checker to make sure I’m not actually sending out unwanted messages.
You’ll need the following to do this project:
Twilio account (upgraded and with a phone number) – Sign up here
BanishBot account – Sign up here
Once your setup with your accounts, go into Twilio functions and create a new function using the blank template.
Name the function something like ‘BanishNewNumber’, then copy and paste this code into the code field – update the username and APIKey fields with your own credentials.
var banishbot = require(‘banishbot’);
var username = ”; // Put your BanishBot username here
var apiKey = ”; // Put your BanishBot API key here
// This script is responsible for banishing a number to the banishbot platform
// This script is usually initiated from a Studio function
// and is passed the number that no longer wishes to be contacted.
exports.handler = function(context, event, callback) {
var numberToBanish = event.NumberToBanish;
console.log(‘Stand back! Im going to Banish the number ‘+numberToBanish);
banishPayload = {“banished”: true, “type”: “PhoneNumber”, “notes”: “STOP request from Studio Flow SMS StudioBot”}
banishbot.banishNewItem(username, apiKey, numberToBanish, banishPayload).then(function(result) {
// Success Result
console.log(result);
callback(null, ‘OK’);
})
.fail(function (error) {
// Error Something died, here is the response
console.log(error);
callback(null, ‘OK’);
});
//callback(null, ‘OK’);
};
Once you have set this function up click save.
Make the second function, called ‘UnbanishNumber’ then copy and paste this code into the code field – update the username and APIKey fields with your own credentials.
var banishbot = require(‘banishbot’);
var username = ”; // Put your BanishBot username here
var apiKey = ”; // Put your BanishBot API key here
// This script is responsible for unbanishing a number.
// This is usually a request from a Studio flow to return SMS to a user.
// This script updates the BanishBot Table to set the banished state to be false for a number.
exports.handler = function(context, event, callback) {
var numberToUnBanish = event.numberToUnBanish;
console.log(‘Stand back! Im going unbanish ‘+numberToUnBanish);
banishPayload = {
banished: false,
notes: ‘This number was un-banished using The BanishBot Studio Flow’
};
banishbot.updateBanishedItem(username, apiKey, numberToUnBanish, banishPayload).then(function(result) {
// Success Result
console.log(result);
callback(null, ‘OK’);
})
.fail(function (error) {
// Error Something died, here is the response
console.log(error);
callback(null, ‘OK’);
});
//callback(null, ‘OK’);
};
Great! A quick recap of the two functions we just created, one is responsible for banishing a number, and the other is responsible for un-banishing a number.
Now let’s go ahead and create our Studio bot that will handle our inbound stop/start requests.
But why build an opt-out bot?
When engaging with consumers, customers or people via SMS you have to comply with carrier compliance requirements, industry standards, and applicable law.
These often include the keywords HELP and STOP. In the case of shortcodes (five/six-digit numbers), you are also required to manage your own blacklist – something BanishBot is designed to do.
This project is going to conform to the highest of standards, that is we are going to manage the following keywords:
STOP, END, CANCEL, UNSUBSCRIBE, QUIT, HELP, INFO, START, and SUBSCRIBE
I’m choosing to adhere to the highest of standards because it means I can use this project/code in a shortcode application without changing any code – handy!
The keywords are broken down into three areas; Stop, Start and Help.
When a user sends a message containing one of the STOP words (STOP, END, CANCEL, UNSUBSCRIBE, QUIT), we are going to banish this number.
When a user sends a message containing one of the START words (START, and SUBSCRIBE), we are going un-banish the number.
When a user sends a message containing one of the HELP words ( HELP, INFO) we are going to reply to the user with details on how they can get in touch – an email address or website for example.
You can find more details on TCPA compliance and industry regulations here: https://support.twilio.com/hc/en-us/articles/223182208-Industry-standards-for-U-S-short-code-HELP-and-STOP
From your Twilio console navigate to Studio and create a new flow, I’ve called mine ‘MatBot’ but feel I recommend you stick with a naming convention relevant to your project.
Your new empty flow will contain just a red trigger box with three connectors attached, one for inbound messages, one for inbound calls and one for REST API requests.
If you aren’t familiar with Studio have a look at the getting started pages.
Today we will be focusing on the SMS opt-out mechanism.
The first ‘widget’ we are going to drag onto the page is the ‘Spit’ Widget. A split is used to help guide how an application will react given different input parameters – in our case the SMS message body.
Drag a split widget onto the flow and link it up to the inbound SMS trigger. It should look something like this:
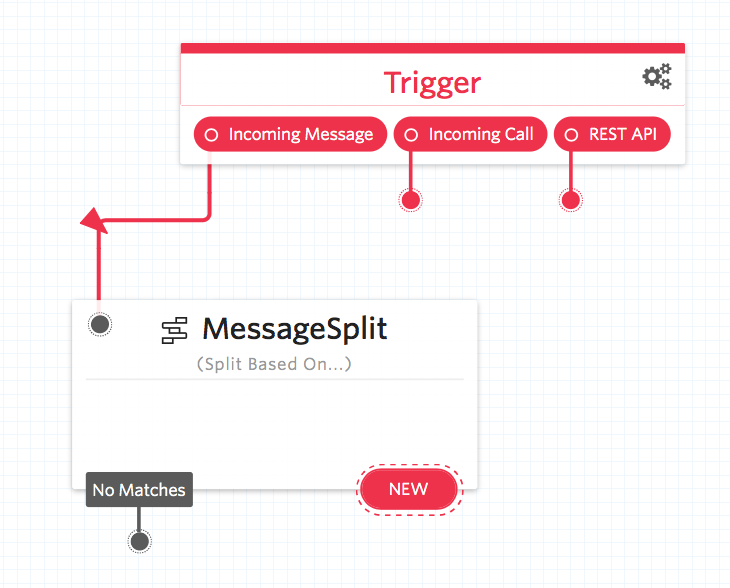
Now when someone sends our number a message, we are going to parse that text and perform different responses based on the message body.
Before we can add any connects let’s drag the rest of the components onto the flow and configure them.
Drag a function widget onto the flow and name it ‘BanishThisNumber’, then from the function drop down select the function ‘BanishNewNumber’ and in the parameters section create a new parameter called ‘NumberToBanish’ with a value of ‘{{trigger.message.From}}’. The {{ brackets }} tells studio that this parameter is dynamic and to use the SenderID we received the message from.
Once you have this widget setup save and then repeat the function setup, this time for the unbanish number function. I called mine ‘UnBanishThisNumber’ linking to function ‘UnbanishNumber’ passing a parameter called ‘numberToUnBanish’ with value ‘{{trigger.message.From}}’.
Great! Now let’s add our first split, click the ‘New’ button, select ‘Regex’ from the drop down and in the value box type STOP. Once you have typed STOP a new drop-down will appear. From the drop-down select the function ‘BanishThisNumber’.
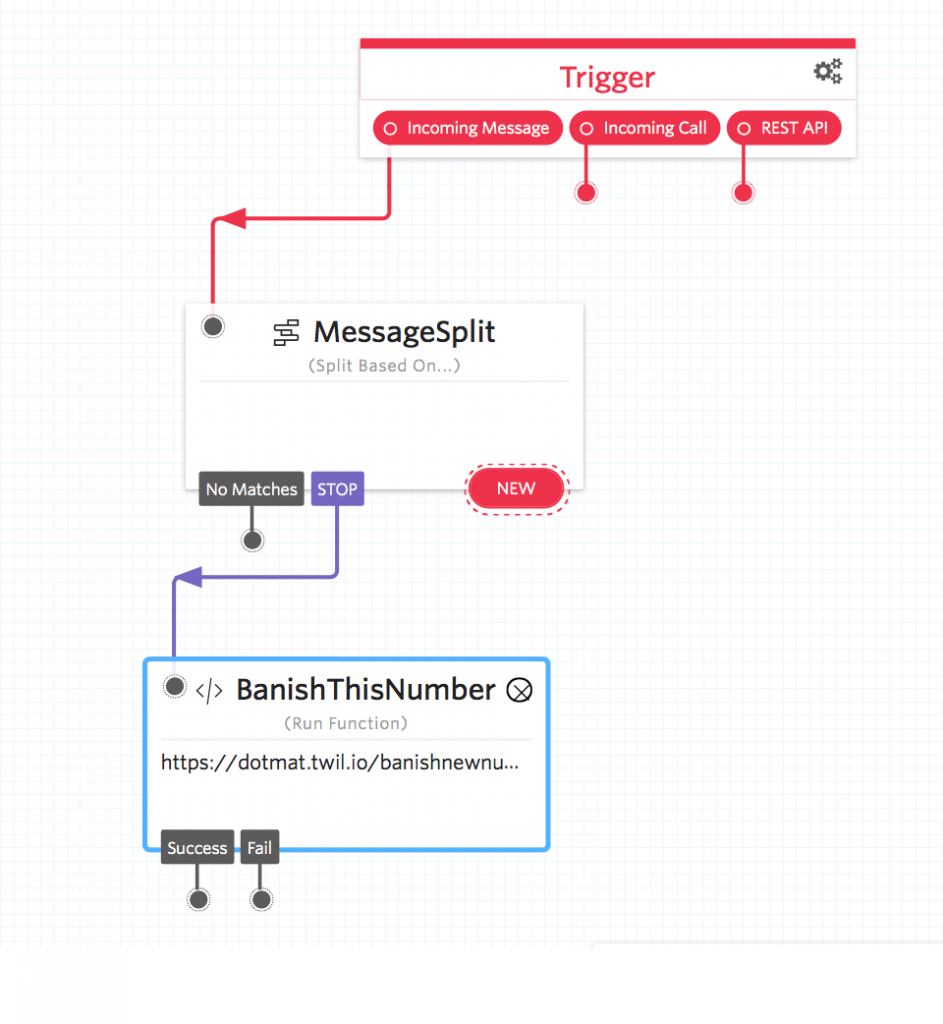
Now when someone sends the message STOP to your number, the studio flow will route the message to the ‘BanishThisNumber’ function which will update the BanishBot service with this number which will now be banished. Now that you have one link setup lets connect the other opt-out keywords; END, CANCEL, UNSUBSCRIBE and QUIT.
Now, this is great but what if a user wants to opt back into your service. To opt a user back in they need to send one of the following words; START or SUBSCRIBE. You can add these words the same way you added the STOP keywords but link the keywords to the function ‘UnBanishThisNumber’.
Finally, we need to add support for the help/information keywords; HELP, INFO.
For help and information, we can reply to the message with a response that directs the user to our helpdesk or email address.
Drag a ‘Send Message’ Widget onto the flow and insert your response message.
Your Studio flow should look something like this:
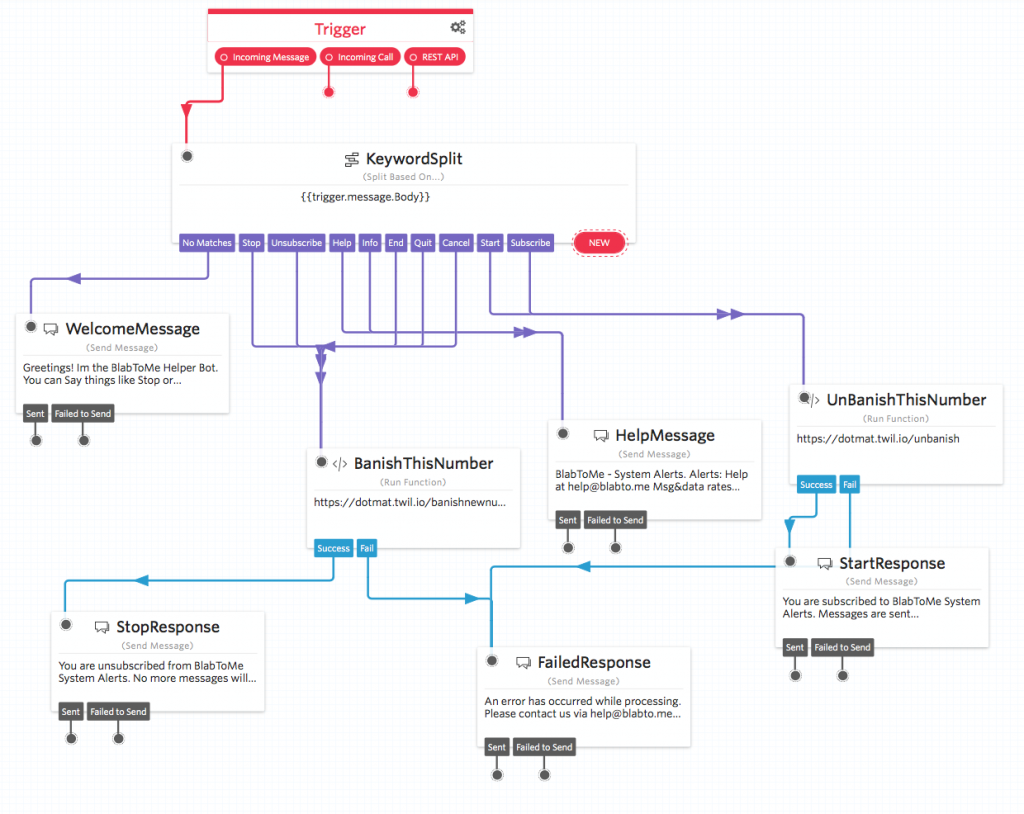
Fantastic! Congratulations on building your opt-out bot!
Now when anyone wants opt-out of your services they will be handled automatically by the studio flow.
For the sending side, you now need to build BanishBot into your sending mechanism, so that each time you want to send someone an SMS message, the sending mechanism first checks the number against BanishBot and rejects the request if the number is indeed banished. – You can find the BanishBot Docs here, https://www.banishbot.com/docs.html
Hope you have fun banishing things 😉